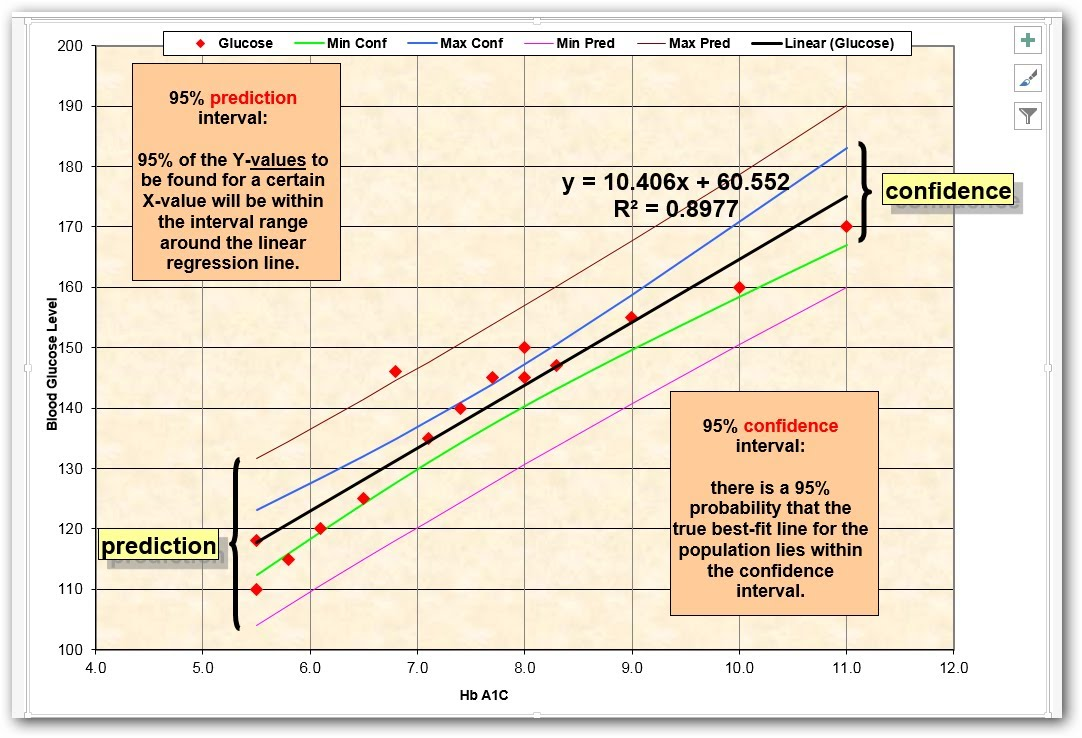
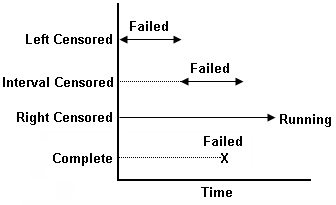
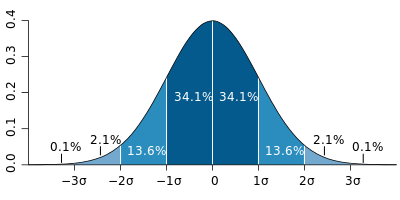
Hazard-based duration model을 이용한 고속도로 돌발상황 지속시간 추정에 관한 연구 http://academic.naver.com/view.nhn?doc_id=9357404&dir_id=0&page=0&query=Hazard-based%20duration%20models&ndsCategoryId=10526 신치현, 김정훈 (2002) 이신혜 (1996) → 처음 이용 / 지속시간모형을 이용한 판매시설 이용자의 주차시간 추정에 관한 연구 What is staus ? http://stat.ethz.ch/R-manual/R-devel/library/survival/html/Surv.html The status indicator, normally 0=alive, 1=dead. Other choices are TRUE/FALSE (TRUE = death) or 1/2 (2=death). For interval censored data, the status indicator is 0=right censored, 1=event at time, 2=left censored, 3=interval censored. Although unusual, the event indicator can be omitted, in which case all subjects are assumed to have an event. https://en.wikipedia.org/wiki/Censoring_(statistics) Distribution 선택을 위한 방법 / 유튜브 https://www.youtube.com/watch?v=rJd3apSGDGI https://github.com/ryandata/Survival/blob/master/Survival.R Survival analysis / confidence interval https://www.yout...